Veljko Milutinovic
CACHING IN SMP:
Understanding the Essence
Partial source: [Tomasevic96] Tomasevic, M., Milutinovic, V.,
“Tutorial on the Cache Coherence Problem
in Shared Memory Multiprocessors: Hardware Solutions”
(Lecture Transparencies; the 1996 update),
IEEE CS Press, Los Alamitos, California, USA, 1993.
Shared Memory Multiprocessing
Architecture (MIMD):
·
Shared memory·
Shared bus·
A set of independent (off-the-shelf) processors with L1 (and L2)Programming model:
·
Simple—essentially the same as for SISDScalability:
·
Limited—memory and bus are the bottleneckMajor problem:
·
Cache consistency maintenance (hw, sw, or hybrid)Major hardware protocols:
·
Snoopy·
Directory
Snoopy protocols
Characteristics
·
Fully distributed information related to coherence·
Responsibility for coherence maintenance on local cache controllers·
Broadcast notification·
Snooping capability·
Ideally suited for bus-based multiprocessors+ Efficient, flexible, low-cost implementation
(almost exclusively used in commercial multiprocessors)
-
Limited scalabilityBasic classes
·
Write-invalidate (WI) protocols·
Write-update (WU) protocols
Write-invalidate protocols
·
Multiple copies with simultaneous read permission·
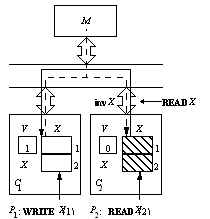
Only one copy with write permission at a time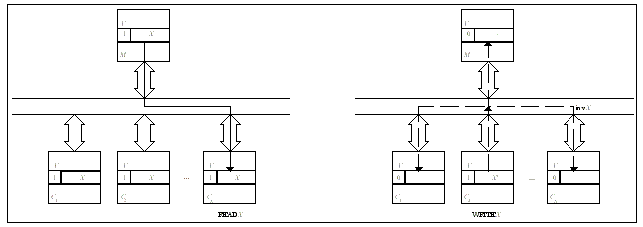
Figure SMPU1: Explanation of a write-invalidate protocol (source: [Tomasevic96]).
Legend:
M—memory,
Ci—cache memory of processor #i,
V—validity bit.
·
Write to a shared copy preceded by an invalidation signal·
Cheap, local writes to an exclusive copy
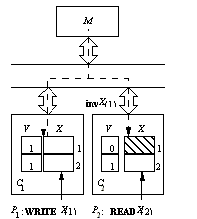
Write-update (WU) protocols
·
Multiple copies with write permission·
Distributed write approach (updated word broadcast to other sharers)
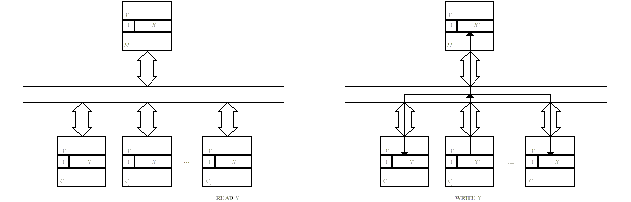
Figure SMPU2: Explanation of a write-update protocol (source: [Tomasevic96]).
Legend: Self-explanatory.
·
Special bus line for dynamic detection of sharing·
Write-back for private data (local writes)·
Write-through for shared dataMOESI
·
Sweazy + Smith, 1986·
Standardization of snoopy cache coherence protocols·
Class of compatible protocols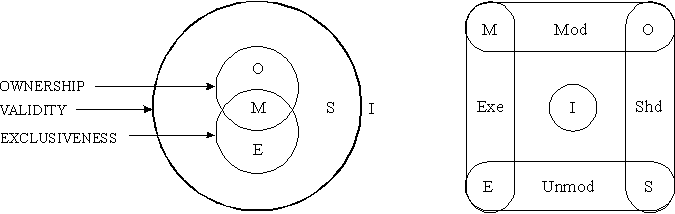
Figure SMPU3: Explanation of the MOESI protocol (source: [Tomasevic96]).
Legend: Self-explanatory.
·
MOESI (Modified, Owned, Exclusive, Shared, Invalid) state model·
Standard superset protocol for the IEEE Futurebus·
Seven special bus lines
·
Coexistence of modules in the same system with different protocols·
Memory system state is consistent·
Number of earlier protocols falls within this class,·
Derived protocol - MESIDirectory protocols
·
Responsibility for coherence maintenance on centralized controller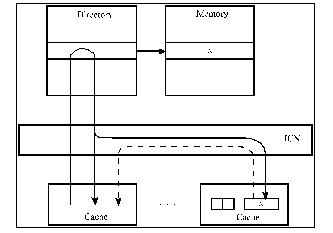
Figure SMPU4: Explanation of a directory protocol (source: [Tomasevic96]).
Legend:
ICN—interconnection network.
·
Individual commands to known locations·
Write-invalidate protocols (most often)·
Suitable for general ICN·
Global information organized in a form of directory:1. full-map directory
2. limited directory
3. chained directory
Full-map directory schemes
·
DirN NB - complete bit vector (a presence bit per processor + dirty bit)·
Two bits in a cache directory entry (valid + modified)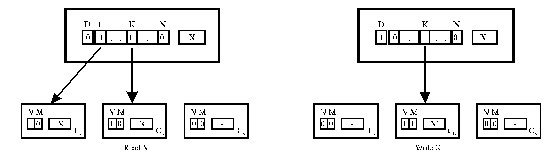
Figure SMPU5: Explanation of a full-map directory scheme (source: [Tomasevic96]).
Legend:
V—validity bit,
M—modified bit,
D—dirty bit,
K—processor which modifies the block.
+
The best performance (the least coherence traffic)-
Directory storage O(MN) ~ O(N2): not scalable-
Centralized controller: a potential fault-tolerance bottleneck-
Inflexible for expansion: adding a new node requires system changes
Limited directory schemes
·
Results of several sharing studies Þ·
Diri X - limited number of pointers (i < N)·
Mechanism to handle pointer overflow·
No-broadcast (X = NB) and broadcast (X = B) variants+ Scalable in terms of directory storage overhead = O(M*log N)
-
Performance affected by increased sharing
Diri NB (No-broadcast scheme)
·
Agarwal, et al., 1989.·
Pointer overflow Þ one shared copy is invalidated to free a pointer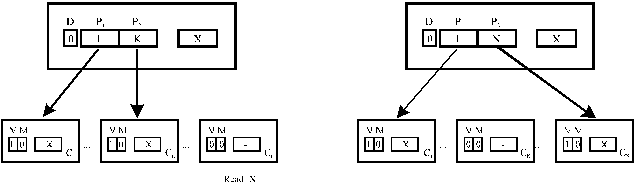
Figure SMPU6: Explanation of the no-broadcast scheme (source: [Tomasevic96]).
Legend: Self-explanatory.
-
Restriction on the number of simultaneously cached copiesPerformance
-
Degradation for intensive sharing of read-only and read-mostly data,
Diri B (Broadcast scheme)
·
No restriction on read sharing·
Pointer overflow Þ broadcast bit set·
Subsequent write Þ invalidation broadcast (some of them unnecessary)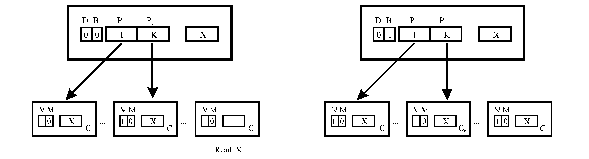
Figure SMPU7: Explanation of the broadcast scheme (source: [Tomasevic96]).
Legend:
D—dirty bit,
B—broadcast bit.
Performance
-
Increased write latency and wasting the communication bandwidthChained directory schemes
·
Distributed directories spread across local caches (chains of pointers)·
Shared copies of a block chained into a list·
Singly- (e.g., SDD) or doubly-linked (e.g., SCI) lists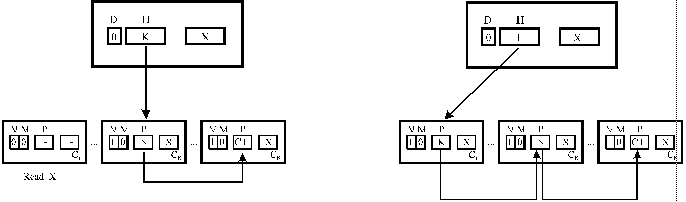
Figure SMPU8: Explanation of chained directory schemes (source: [Tomasevic96]).
Legend:
H—header.
+
Reduced directory storage (~ O(log N)), without the restriction of sharing+ No serialization of replies in main memory (no bottleneck)
-
Higher write latency and increased complexity·
Performance close to the full-map schemes [Chaiken90]
Veljko Milutinovic
CACHING IN SMP:
State of the Art
LimitLESS Directory Protocols
·
Agarwal et al., MIT.·
Standard limited directory protocol (diriB or diriNB),·
If pointer overflow, then interrupt: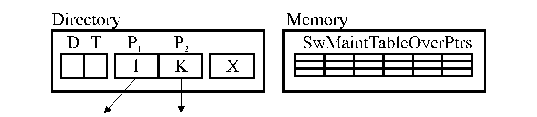
Figure SMPS1: LimitLESS directory protocol (source: [Agarwal90], [Agarwal91]).
Legend:
D—dirty bit; T—trap bit; SwMaintTableOverPtrs—Software Maintained Table of Overflow Pointers.
References:
[Agarwal90] Agarwal, A., Lim, B.-H., Kranz, D., Kubiatowicz, J., “April: A Processor Architecture for Multiprocessing,”
Proceedings of the ISCA-90, May 1990, pp. 104–114.
[Agarwal91] Agarwal, A., Lim, B.-H., Kranz, D., Kubiatowicz, J., “LimitLESS Directories: A Scalable Cache Coherence Scheme,”
Proceedings of the ASPLOS-91, April 1991, pp. 224–234.
Dynamic Pointer Allocation Protocols
·
Simoni, Stanford.·
Directory entry:1. Short directory: directory header (DirtyState bit + HeadLink field)
2. Long directory: pointer/link store (set of two-field linked lists)
·
Pointer/link store:1. One linked list of free pointer/link store entries
2. Linked lists for shared cache blocks (processor pointer + link)
·
A hardware implementation of LimitLESS!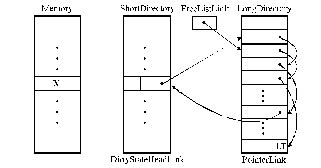
Figure SMPS2: Dynamic pointer allocation protocol (source: [Simoni90, Simoni91, Simoni92]).
Legend:
X—CacheBlock; LT—list terminator; DirtyState (1 bit); HeadLink (22 bits); Pointer (8 bits); Link (22 bits); P/L—Pointer/Link Store.
References:
[Simoni90] Simoni, R., “Implementing a Directory-Based Cache Coherence Protocol,” Stanford University, CSL-TR-90-423, Palo Alto, California, USA, March 1990.
[Simoni91] Simoni, R., Horowitz, M., “Dynamic Pointer Allocation for Scalable Cache Coherence Directories,”
Proceedings of the International Symposium on Shared Memory Multiprocessing, Stanford University, Palo Alto, California, USA, April 1991, pp. 72–81.
[Simoni92] Simoni, R., “Cache Coherence Directories for Scalable Multiprocessors,” Ph.D. Thesis, Stanford University, Palo Alto, California, USA, 1992.
SCI: A Cache-Based Doubly-Linked-List Protocol
·
Problem: Scalability and Standardization·
Idea: IEEE 1596–1992 SCI Standard·
Reading a shared value:·
Writing to a shared value:·
Advantages of doubling the links:
Figure SMPS3: An explanation of the SCI protocol (source: [James90]).
Legend:
V—validity (1 bit); MemHeadPtr (8 bits); State (5 bits); ForwPtr (8 bits); BackPtr (8 bits).
Reference:
[James90] James, D., Laundrie, A., Gjessing, S., Sohi, G., “Distributed-Directory Scheme: Scalable Coherent Interface,”
IEEE Computer, Vol. 23, No. 6, June 1990, pp- 74–77.
RST (Reduced State Transitions)
·
Prete, University of Pisa, 1991.·
Goals:a. to minimize the write-backs (due to replacements of mod-shd copies)
b. to simplify the implementation
·
Based on Dragon (and Firefly):·
Difference to Dragon:a. every write transaction updates the memory block involved
b. unmod-shd to mod-shd transaction avoided
·
Difference to Firefly:·
shared memory includes a data buffer·
only one supplier (modified copy or memory) on read missPerformance
+ Reduced number of write-backs
-
Lower probability of cache supplyReference:
[Prete91] Prete, C. A.,
“RST,”
IEEE Micro, April 1991, pp. 16–19, 40–52.
USCR (Useless Shared Copies Removal)
·
Problem for WU: false sharing due to process migration·
Idea: detecting and destroying the remaining copies·
Protocol requirements (in addition to Dragon):a) Invalid state
b) LUP (Last Using Process) bit for each cache block
c) CP (Current Process) bit in control register
d) Dirty line
·
Basic protocol actions (for reducing of false sharing)a) CP is stored in LUP on each processor operation on this block
b) CP is complemented on every process switch
c) on each bus operation, check for an unused copy of the block
(CP
d) when a dirty copy is to be invalidated, requester inherits the ownership
·
Performance+
-
Not all unused copies eliminatedReference: Prete, C. A., Riccardi, L., Prina, G., “Reducing Coherence-Related Overhead in Multiprocessor Systems,”
Proceedings of the IEEE/Euromicro Workshop on Parallel and Dstributed Processing, San Remo, Italy, January 1995, pp. 444–451.
UPCR (Useless Passive Copies Removal)
·
Problem for WU: passive sharing due to process migration·
Idea: modification of the general UCR strategyReference:
[Prete97] Prete, C. A., “UPCR,” IEEE TCCA Newsletter, March 1997, pp. ___–___.
Veljko Milutinovic
CACHING IN SMP:
IFACT
WIN (Word INvalidate protocol)
·
Tomasevic + Milutinovic, University of Belgrade, 1991.·
Finer-grain, partial block invalidation|
|
|
|
Full Block Invalidation |
Partial Block Invalidation |
Figure SMPI1: Explanation of the WIN protocol—essence (source: [Tomasevic92a], [Tomasevic92b]).
Legend:
M—memory.
·
Word invalidation Þ existence of partially valid blocks:1. IW1 - one invalid word in a partially valid block
2. IW2 - two invalid words in a partially valid block
·
Block ownership·
Dynamic recognition of sharing status·
Pollution point - criterion of inactive sharing·
Read word bus operationOperation |
C1 |
C2 |
C3 |
initial state |
unmod-shd |
mod-shd |
unmod-shd |
P1: Write X(3) |
mod-shd |
IW1(3) |
IW1(3) |
P1: Write X(4) |
mod-shd |
IW2(3,4) |
IW2(3,4) |
P3: Read X(2) |
mod-shd |
IW2(3,4) |
IW2(3,4) |
P3: Read X(3) |
mod-shd |
IW2(3,4) |
IW1(4) |
P3: Write X(4) |
IW1(4) |
IW2(3,4) |
mod-shd |
P3: Write X(1) |
IW2(1,4) |
invalid |
mod-shd |
P3: Write X(2) |
invalid |
invalid |
mod-exc |
Figure SMPI2: Explanation of the WIN protocol—details(source: [Tomasevic92a], [Tomasevic92b]).
Legend:
IW1/2—newly introduced states.
Performance
·
Less invalidation misses, higher hit ratio Þ better data utilization·
Reduced false sharing·
Appropriate sequential pattern of sharing·
Additional complexity: one state bit per block + one valid bit per wordReference:
[Tomasevic92a] Tomasevic, M., Milutinovic, V.,
“A Simulation Study of Snoopy Cache Coherence Protocols,”
Proceedings of the HICSS-92, Koloa, Hawaii, USA, 1992, pp. 427–436.
[Tomasevic92b] Tomasevic, M.,
“A New Snoopy Cache Coherence Protocol,”
Ph.D. Thesis, University of Belgrade, Belgrade, Serbia, Yugoslavia, 1992.
The STS/MOESIA
Current Research:
STS/MOESIA
STS/SMP (SiliconCompilationVLSI)
STS/DSM (SiliconCompilationVLSI)
References:
[Milutinovic95a] Milutinovc, V.,
“The Split Temporal/Spatial Cache Memory,”
UBTR, Belgrade, Serbia, Yugoslavia, 1995.
[Milutinovic95b] Milutinovic, V.,
http://ubbg.etf.rs/~emilutiv/ieee90.html
Comment:
SUN - JAVA’/JAVA”
The CICA/RM
Current Research:
MemoryLess
MemoryFull
SmartHybrid
References:
[Milutinovic95c] Milutinovic, V.,
“New Ideas for SMP/DSM,”
UBTR, Belgrade, Serbia, Yugoslavia, 1995.
[Milutinovic95d] Milutinovic, V.,
http://ubbg.etf.rs/~emilutiv/ieee90.html
Comment:
INTEL - P7/P8